leveldb源码阅读
文章结构
- 01.前期准备
- 02.整体架构与相关图解
- 03.写数据分析
- 04.读数据分析
- 05.LRU与skiplist实现
- 06.compact分析
- 07.多种iter实现
- 08.系统api对接调用
01. 前期准备
版本 v1.20
编译
# master
git clone --recurse-submodules https://github.com/google/leveldb.git
# v1.20
git checkout v1.20
# 生产版本
make
# 调试版本
make OPT=-g2
# demo项目
# 设置动态库路径,用CDT的时候 把这个配置run configuration的环境变量中
export LD_LIBRARY_PATH=/home/xxx/004.work/001.workspace/02.cpp-200803/leveldb-demo/libs
#修改makefile
LIBS = /home/xxx/004.work/001.workspace/02.cpp-200803/leveldb-demo/libs/*.so
# 配置CDT
# 增加build 环境变量
CPLUS_INCLUDE_PATH=/home/xxx/500.xx/600.self/002.code/02.cpp/004.level/leveldb/include02. 整体架构与相关图解
一些关键词与基本概念
LSM appendonly 写性能友好 MemTable sst/ldb文件 WAL skiplist LRU MANIFEST
leveldb是LSM-Tree的一个实现。LSM-Tree 由三个数据结构组成:内存表分为 Memtable 和 ImmutableTable,磁盘上的 ldb(SSTable) 文件。写内存表时会先写WAL,即log文件,用于恢复等。
相关图解
leveldb中skiplist跳表图解
leveldb中LRU cache图解
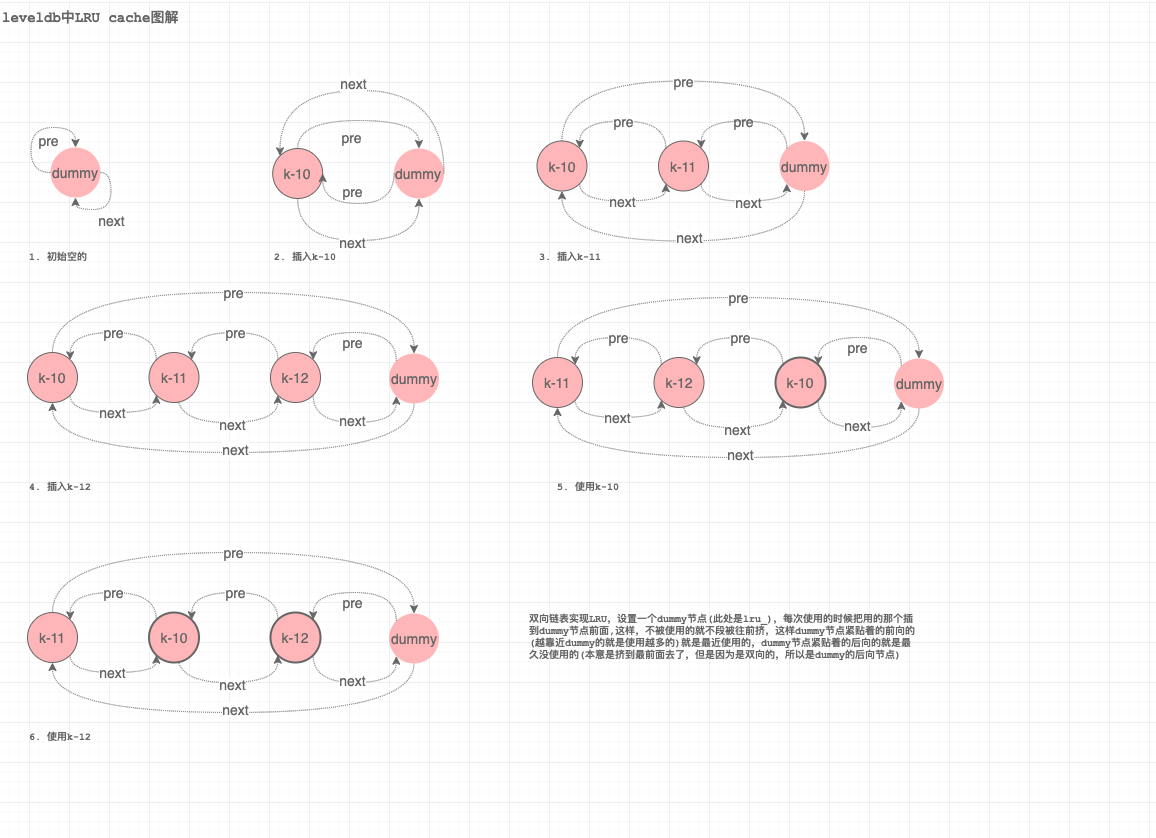
leveldb中文件格式图解-MANIFEST文件
leveldb中文件格式图解-ldb(sst)文件

03. 写数据分析
在leveldb的整体架构上来说,写数据是先写log再写MemTable,MemTable到一定大小时再compact刷盘。
写流程
DBImpl::MakeRoomForWrite 此处主要完成MemTable已用大小的检查,并对如果MemTable满了之后的处理。当MemTable到一定大小(默认4MB)时,就会触发compact刷盘,就是在此处完成逻辑判断的。当MemTable满了且imm table未完成compcat刷盘,那么就在此等待。此外,当MemTable满了且L0文件太多也会在此等待。
// db_impl.cc // line 1341 else if (!force && (mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) { // options_.write_buffer_size默认是4MB。是否超过compact刷盘阈值的判断。 // There is room in current memtable break;// 正常是走到这个分支break,因为有空间可以直接写 // ........... // line 1345 } else if (imm_ != NULL) { // 这个分支表示写的太快了, MemTable满了且imm table未完成compcat刷盘,那么就在此等待 // We have filled up the current memtable, but the previous // one is still being compacted, so we wait. Log(options_.info_log, "Current memtable full; waiting...\n"); bg_cv_.Wait(); } else { // ........... // line 1375 MaybeScheduleCompaction(); // 触发compact刷盘 }
Writer::AddRecord log_writer.cc line36 写WAL log。
- 根据block上还剩的大小来确定能否写得这次的数据,进而推断出RecordType。RecordType分为kFullType、kFirstType、kLastType、kMiddleType。能完全写得下的称之为kFullType,只能写前面一部分的为kFirstType,只能写后面一部分的为kLastType,只能写中间一部分的为kMiddleType。
- Writer::EmitPhysicalRecord log_writer.cc line84写物理记录,即写WAL日志,即数据目录下的xxx.log。写的方式也比较简单,先写header再写数据,数据定长。
- header长度为7,索引0
3的这四个byte为数据的crc值通过fixed32方式编码的结果,索引45的两个byte表示长度。索引6的这个byte表示上一步推导出来的类型。 - 写完header后在后面append数据。然后更新block_offset_,更新的逻辑就是在原来他的值的基础上加上header size和数据的长度。
- header长度为7,索引0
♨ hexdump -C /tmp/testdb02/000163.log 00000000 64 04 5f 0c 1c 00 01 5f 88 1e 00 00 00 00 00 01 |d._...._........| 00000010 00 00 00 01 03 6b 2d 63 0a 68 65 6c 6c 6f 2d 31 |.....k-c.hello-1| 00000020 31 2d 63 |1-c| 00000023这是我写完log后文件的内容,我demo中写如的key是k-c,value是hello-11-c。
MemTable::Add memtable.cc line82 分配内存并组织需要插入MemTable的数据buf。buf的具体的组织形式是:第一个byte是internal_key_size以Varint32编码后的值,internal_key_size是key的大小加8。接下来是key的数据。接下来8个byte是SequenceNumber和type(指ValueType,即在demo case中此处是kTypeValue)合在一起后以Fixed64编码后的值。合的方式是(SequenceNumber << 8) | type。相当于后一位给type用。接下来的一个byte是val_size以Varint32编码后的值。接下来是value的数据。
SkipList<Key,Comparator>::Insert skiplist.h line 337 将key引用插入MemTable。 MemTable的内部数据结构是一个
skiplist。本系列文章中有章节会详细描述关于skiplist,此处不再赘述。
写入过程的关键调用堆栈:
Thread #1 [leveldb-demo] 3045680 [core: 3] (Suspended : Step)
leveldb::SkipList<char const*, leveldb::MemTable::KeyComparator>::Insert() at skiplist.h:341 0x7ffff7d7c509
leveldb::MemTable::Add() at memtable.cc:105 0x7ffff7d7bae4
leveldb::(anonymous namespace)::MemTableInserter::Put at write_batch.cc:118 0x7ffff7d8e795
leveldb::WriteBatch::Iterate() at write_batch.cc:59 0x7ffff7d8e487
leveldb::WriteBatchInternal::InsertInto() at write_batch.cc:133 0x7ffff7d8e882
leveldb::DBImpl::Write() at db_impl.cc:1,233 0x7ffff7d6c41a
leveldb::DB::Put() at db_impl.cc:1,479 0x7ffff7d6d61e
leveldb::DBImpl::Put() at db_impl.cc:1,187 0x7ffff7d6c081
testPutDbSingleKey() at leveldb-demo.cpp:98 0x4018c9
main() at leveldb-demo.cpp:222 0x4015c904. 读数据分析
在leveldb的整体架构上来说,读数据是先查找MemTable mem;找不到则查找MemTable imm,MemTable内部的数据结构是skiplist;再找不到则查找current(Version),这个Version背后对应的是ldb(老版本是sst文件,下同)文件。
sst:Sorted String Table
读流程
构造LookupKey,LookupKey结构如下:
LookupKey + + + + <+最大长度5+> <-+固定长度8+> | | | | +--------------------------------------------------------------+ | | | | | | | | | | | | +-----------+-------------------------------------+------------+ ① ② ③ ④ + + + + | | | | | | | | | | | v end_ | | | | | | ③和④之间是seqNum和vauleType | | | 经EncodeFixed64后数据 | | v | | ②和③之间是key的数据 | | | +---->kstart_ | ①和②之间存放key长度 | 此处key长度指加8后且经过EncodeVarint32编码的数据 +----->start_ 注:如果字符图显示的格式不对,是因为系统等宽字体等问题,可以考虑贴到其他编辑器中查看EncodeVarint32 最多5个char
PackSequenceAndType 8个char
查找mem(MemTable),MemTable内部是一个跳表SkipList,整个查询过程遵循跳表的查询逻辑。具体可以参见跳表章节。查到则退出。
查找imm(MemTable),因为都是MemTable,所以逻辑同上。
Version::Get version_set.cc line 332 查找current(Version),这个是查找sst的过程。
先找到在哪个sst中,Version::Get version_set.cc line 356 ~ line 390。
sst 文件按level组织,默认7个level。 查找sst时,按level进行迭代。level 0特殊处理。
level 0的挨个迭代sst。非level 0 的按二分查找的方式进行查找,FindFile version_set.cc line 86。因为非level 0的多个sst的key的范围是有序的,比如:sst 0 对应 a
d,sst 1 对应 eh,sst 2 对应 i~p… 基于这个有序的规律的前提,就可以进行二分查找了。level 0 的不是有序的,可能存在范围重叠,所以要挨个迭代。每个sst文件中的key是有序的,且对应一定范围的key。sst对应的key的范围的值,即最大key和最小key是在MANIFEST文件中记录的,关于MANIFEST文件的格式与解析可以参见相关章节。 查找sst时,迭代sst的过程中,会将我们要查找的目标key和sst文件对应的key范围进行比较,落在这个范围内的,说明要查找的key在这个sst文件中。
获取sst文件对应的数据,有缓存机制。 ableCache::FindTable, table_cache.cc line 48。 上一步确定了在哪个sst文件中之后,接下来就是在文件中定位对应的key。文件与其对应的数据有一层ShardedLRUCache缓存。此时会先从ShardedLRUCache缓存中查,查不到再打开物理文件读取对应数据。
查找缓存
*handle = cache_->Lookup(key); // table_cache.cc line 51。 cache_ 实例是 cache_(NewLRUCache(entries))查LRUCache的调用栈如下:
Thread #1 [leveldb-demo] 10459 [core: 3] (Suspended : Step) leveldb::(anonymous namespace)::HandleTable::Lookup at cache.cc:78 0x7ffff7d9830c leveldb::(anonymous namespace)::LRUCache::Lookup at cache.cc:257 0x7ffff7d98ab2 leveldb::(anonymous namespace)::ShardedLRUCache::Lookup at cache.cc:368 0x7ffff7d99395 leveldb::TableCache::FindTable() at table_cache.cc:51 0x7ffff7d80949 leveldb::TableCache::Get() at table_cache.cc:112 0x7ffff7d80ddc leveldb::Version::Get() at version_set.cc:408 0x7ffff7d83eac leveldb::DBImpl::Get() at db_impl.cc:1,141 0x7ffff7d6bcf0 testGetdb() at leveldb-demo.cpp:40 0x40577b main() at leveldb-demo.cpp:217 0x4015c9
- 打开物理文件读取数据
调用系统调用open打开文件,并调用系统调用mmap映射文件到内存, env_posix.cc line 347。
virtual Status NewRandomAccessFile(const std::string& fname,
RandomAccessFile** result) {
*result = NULL;
Status s;
int fd = open(fname.c_str(), O_RDONLY); // 打开
if (fd < 0) {
s = IOError(fname, errno);
} else if (mmap_limit_.Acquire()) {
uint64_t size;
s = GetFileSize(fname, &size);
if (s.ok()) {
void* base = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0); // 映射到内存
if (base != MAP_FAILED) {
*result = new PosixMmapReadableFile(fname, base, size, &mmap_limit_);
} else {
s = IOError(fname, errno);
}
}
close(fd);
if (!s.ok()) {
mmap_limit_.Release();
}
} else {
*result = new PosixRandomAccessFile(fname, fd, &fd_limit_);
}
return s;
}
mmap映射后,当需要读取数据时直接操作内存即可。
调用系统调用open打开文件的调用栈:
Thread #1 [leveldb-demo] 21700 [core: 4] (Suspended : Step)
__libc_open64() at open64.c:40 0x7ffff7a24e79
leveldb::(anonymous namespace)::PosixEnv::NewRandomAccessFile at env_posix.cc:351 0x7ffff7d9c6c8
leveldb::TableCache::FindTable() at table_cache.cc:56 0x7ffff7d809c3
leveldb::TableCache::Get() at table_cache.cc:112 0x7ffff7d80ddc
leveldb::Version::Get() at version_set.cc:408 0x7ffff7d83eac
leveldb::DBImpl::Get() at db_impl.cc:1,141 0x7ffff7d6bcf0
testGetdb() at leveldb-demo.cpp:40 0x40577b
main() at leveldb-demo.cpp:217 0x4015c9
读取数据的调用栈:
Thread #1 [leveldb-demo] 21700 [core: 3] (Suspended : Step)
leveldb::(anonymous namespace)::PosixMmapReadableFile::Read at env_posix.cc:204 0x7ffff7d9bc7f
leveldb::Table::Open() at table.cc:50 0x7ffff7d95265
leveldb::TableCache::FindTable() at table_cache.cc:64 0x7ffff7d80ae0
leveldb::TableCache::Get() at table_cache.cc:112 0x7ffff7d80ddc
leveldb::Version::Get() at version_set.cc:408 0x7ffff7d83eac
leveldb::DBImpl::Get() at db_impl.cc:1,141 0x7ffff7d6bcf0
testGetdb() at leveldb-demo.cpp:40 0x40577b
main() at leveldb-demo.cpp:217 0x4015c9
- 读取并解析sst文件footer区域,index对应的区域。
sst文件不同于我们一般接触到的MANIFEST文件或者其他常规玩法,他是将魔法数字、一些标志性数据放在了文件末尾,称之为footer区域。
解析footer区域,相应代码如下,具体数据组织形式可以参见文件格式和图解章节。footer区域中index元数据、meta数据、魔法数字等内容。
// table.cc line 53
Footer footer;
s = footer.DecodeFrom(&footer_input);
// format.cc line 43
Status Footer::DecodeFrom(Slice* input) {
const char* magic_ptr = input->data() + kEncodedLength - 8;
const uint32_t magic_lo = DecodeFixed32(magic_ptr);
const uint32_t magic_hi = DecodeFixed32(magic_ptr + 4);
const uint64_t magic = ((static_cast<uint64_t>(magic_hi) << 32) |
(static_cast<uint64_t>(magic_lo)));
if (magic != kTableMagicNumber) {
return Status::Corruption("not an sstable (bad magic number)");
}
Status result = metaindex_handle_.DecodeFrom(input);
if (result.ok()) {
result = index_handle_.DecodeFrom(input);
}
if (result.ok()) {
// We skip over any leftover data (just padding for now) in "input"
const char* end = magic_ptr + 8;
*input = Slice(end, input->data() + input->size() - end);
}
return result;
}
从footer区域中拿到index区域的元数据(包括index实际区域的大小size和offset,offset是指从文件的哪里开始是index的实际区域)后,解析index的实际区域。解析index实际数据区的调用栈如下:
Thread #1 [leveldb-demo] 21700 [core: 4] (Suspended : Step)
leveldb::ReadBlock() at format.cc:69 0x7ffff7d92356
leveldb::Table::Open() at table.cc:65 0x7ffff7d953aa
leveldb::TableCache::FindTable() at table_cache.cc:64 0x7ffff7d80ae0
leveldb::TableCache::Get() at table_cache.cc:112 0x7ffff7d80ddc
leveldb::Version::Get() at version_set.cc:408 0x7ffff7d83eac
leveldb::DBImpl::Get() at db_impl.cc:1,141 0x7ffff7d6bcf0
testGetdb() at leveldb-demo.cpp:40 0x40577b
main() at leveldb-demo.cpp:217 0x4015c9
- 通过index数据构建Block::NewIterator,以及确定`num_restarts`等信息。`num_restarts`的值是在index区,Fixed32编码的,且在这个区域的最尾端(标志性数据又是以编码在尾端的方式存储的)。
Iterator* Block::NewIterator(const Comparator* cmp) {
if (size_ < sizeof(uint32_t)) {
return NewErrorIterator(Status::Corruption("bad block contents"));
}
const uint32_t num_restarts = NumRestarts(); // 读取index区 确定num_restarts值,Fixed32编码的, 在index区最尾端。
if (num_restarts == 0) {
return NewEmptyIterator();
} else {
return new Iter(cmp, data_, restart_offset_, num_restarts);
}
}
- 根据上一步构造出来的Block Iterator,seek出查找的目标的key在哪里。 Block::Iter Seek block.cc line 165
几个关键函数与步骤
1. 根据restarts的num用二分查找确定在索引restarts中最靠近我们要查的目标key的 key' 的指针位置(内存地址)
data_ 对象的地址是index区开始的地方, restarts_ 表示“key的指针的相对位移”开始的地方(即**相对位移开始的地方**,其他都是修饰),key的指针的**相对位移 用Fixed32表示**,长度是 sizeof(uint32_t)),是第多少个key,就加上 多少\*sizeof(uint32_t)),“第多少个”在上式中就是index。**data_ 到 restarts_之间**的数据是**索引的key**的存放区(真正的kv还不在这个地方,真正的kv在data_ 之前,这个地方只是**单纯的编入索引的key**)。所以key' 的指针位置是落在索引数据区内的,不是数据区的那个kv的key的指针哈。 数据组织的具体细节可以参考图解与文件格式相关章节。
// block.cc line 172
uint32_t region_offset = GetRestartPoint(mid);
// block.cc line 99
uint32_t GetRestartPoint(uint32_t index) {
assert(index < num_restarts_);
return DecodeFixed32(data_ + restarts_ + index * sizeof(uint32_t)); // 根据restarts的num确定key'的指针位置
}
2. 从key' 开始依次查找索引中最靠近我们key的 key''。 ParseNextKey。
// block.cc line 195
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
3. 当确定的key'' 还不是目标key本身时(只是最近接,可能不等),基于前面两步确定的数据到真正数据区依次查找。逻辑与1 、2步骤相同,因为复用的一个方法。到真正数据区依然有restarts_的概念,可以近似理解成“又是一级索引,只是个数不多,我调试时发现只有9个”,不同的是这次到步骤2时,如果查找的目标key在db中存在,那就一定能精确命中,因为到真正数据区了嘛,再找不到就是没有了。key对应的值也在此处能找出来了。
4. 步骤3推到了saver.state为kFound,在Version::Get中case到kFound return。同时有个说明:由0~config::kNumLevels-1层(level)进行寻找 找到了就在此处return。对于一个key写多次的 他能保证最后一次写的 能被先读到 那么最后一次读的就是最新值。- 按需判断是否要compcat。 MaybeScheduleCompaction。再做一些释放工作,至此,查询过程结束。
05. LRU cache与skiplist实现
LRU cache
在leveldb中,sst的数据是用LRU cache缓存,准确的说,用的应该是ShardedLRUCache,ShardedLRUCache是基于LRU cache上面做了一层分片。具体使用的详情参见《读数据分析》章节的Version::Get部分。
LRU cache的实现在LRUCache类中,cache.cc line 153。
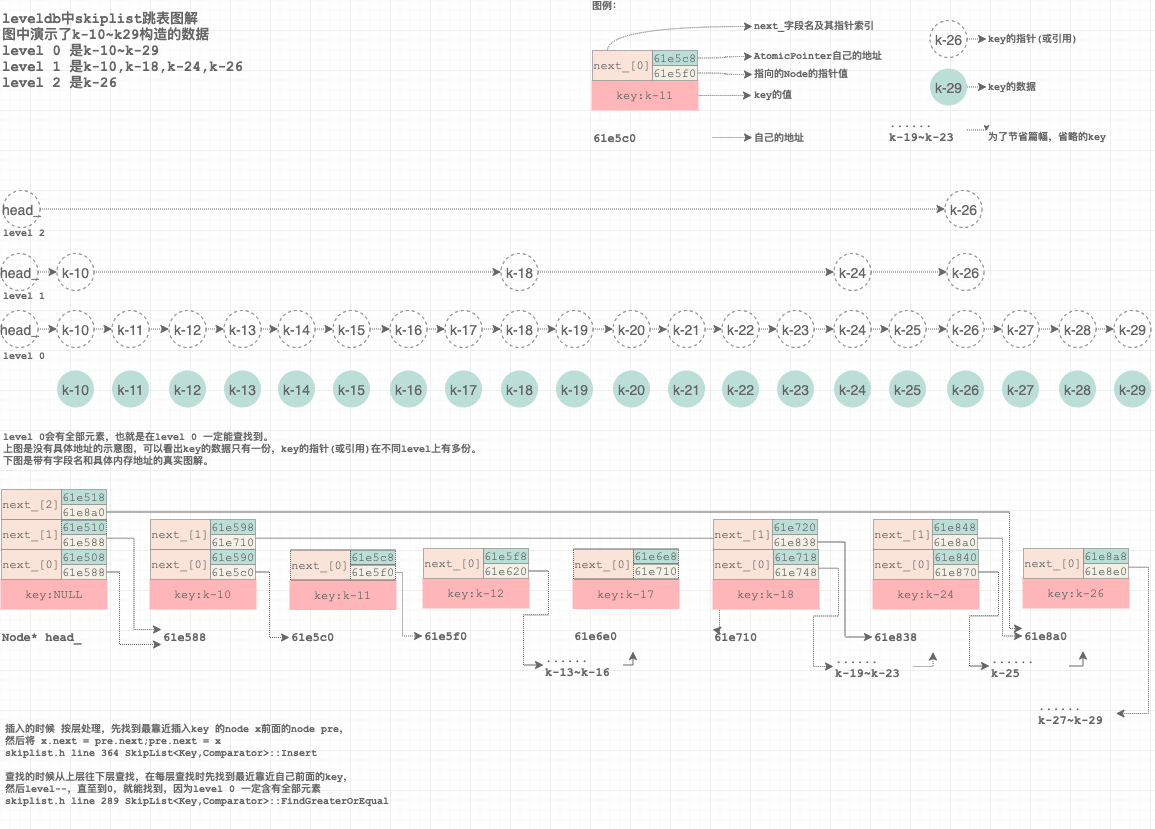
怎么实现LRU?简单地说是,双向链表实现LRU,设置一个dummy节点(此处是lru_),每次使用的时候把用的那个插到dummy节点前面,这样,不被使用的就不段被往前挤,这样dummy节点紧贴着的前向的(越靠近dummy的就是使用越多的)就是最近使用的,dummy节点紧贴着的后向的就是最久没使用的(本意是挤到最前面去了,但是因为是双向的,所以是dummy的后向节点)。
初始化
dummy节点lru_都是自己:
// cache.cc line 200
LRUCache::LRUCache()
: usage_(0) {
// Make empty circular linked lists.
lru_.next = &lru_;
lru_.prev = &lru_;
in_use_.next = &in_use_;
in_use_.prev = &in_use_;
}查找使用
Lookup一次 refs加1,并从所在位置挪掉,并append到lru_前面去:
// cache.cc line 255
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
LRUHandle* e = table_.Lookup(key, hash);
if (e != NULL) {
Ref(e);
}
return reinterpret_cast<Cache::Handle*>(e);
}
void LRUCache::Ref(LRUHandle* e) {
if (e->refs == 1 && e->in_cache) { // If on lru_ list, move to in_use_ list.
LRU_Remove(e);
LRU_Append(&in_use_, e);
}
e->refs++;
}插入
插入时,如果容量满了,要挤掉最老的
// cache.cc line 293
while (usage_ > capacity_ && lru_.next != &lru_) {
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}skiplist
其是MemTable的内部数据结构。
其实现在skiplist.h中。
打印
对于skiplist来说,我们只需要打印出内部结构,就能一目了然地清晰地观察跳表的结构及其内部数据,于是我写了一段简单的打印代码:
void toStringForSLevel(int level) const {
Node* x = head_;
int maxlevel = GetMaxHeight() - 1;
if (level > maxlevel) {
return;
}
Node* next = x->Next(level);
if (next == NULL) {
return;
}
std::cout << "level:" << level << ": " << std::endl;
std::cout << "level:" << level << ": " << next->key << std::endl;
while (true) {
Node* innerNext = next->Next(level); // 一直迭代next 的leve位置就可以了,这个有点不同于我们正常理解的方式,其实他一个横纵的结构。可以参见跳表的图。
if (innerNext == NULL) {
break;
}
std::cout << "level:" << level << ": " << innerNext->key << std::endl;
next = innerNext;
}
return;
}
void toString() const {
int maxlevel = GetMaxHeight();
for (int i = 0; i < maxlevel; i++) {
toStringForSLevel(i);
}
}改代码需要include iostream这个lib,然后插入在GetMaxHeight函数后面(下方),具体结构可以参见 相关图解章节,可以一目了然。
06. compact分析
本章节有参考网路上部分文章与材料。
相关概念
compact分两大类,第二类又分三种小的:
- Minor Compaction。memTable写满之后,转成imm后落地到磁盘sst文件的过程。
- Major Compaction。
- 手动compact。调用levedb的api DBImpl::CompactRange(const Slice begin, const Slice end)达成,比如ceph就这么干的。
- sst文件大小超出阈值后compact。size compact。每个level的文件总和有个阈值,每次会进行当前的size总和除以阈值来计算score,当score超出范围后选择最大的score对应的level进行compact。每个level的文件总和的阈值不同,level越大,阈值越大。
- 查找时未能命中次数超过阈值后compact。seek compact。
Major Compaction过程中主要做哪些逻辑,也就是compact了啥?
- 均衡各个level的数据,保证 read 的性能;
- 合并delete数据,释放磁盘空间,因为leveldb是采用的延迟(标记)删除;
- 合并update的数据,例如put同一个key,新put的会替换旧put的,虽然数据做了update,但是update类似于delete,是采用的延迟(标记)update,实际的update是在compact中完成,并实现空间的释放。
compact过程
选择进行合并的文件
函数VersionSet::PickCompaction用于构建出一次合并对应的Compaction结构体。来看这个函数主要的流程。
在挑选哪些文件需要合并时,依赖于两个原则:
- 首先考虑每一层文件的数量:这个数量的计数,对应到Version的compaction_score_中,在每次VersionSet::Finalize函数中,都会首先进行预计算这个值,那个级别的分数高,下一次就优先选择该层次来做合并。对于不同的层次,计算的规则也不同:
- level 0:0级文件的数量除以kL0_CompactionTrigger来计算分数。
- 非0级:该层次的所有文件大小/MaxBytesForLevel(level)来计算分数。
- 如果上面的计算中,compaction_score_为0,那么就需要具体针对一个文件来进行合并。leveldb中,在FileMetaData结构体里有一个成员allowed_seeks,表示在该文件中查询某个键值时最多允许的定位次数,当这个值为0时,意味这个文件多次查询都没有查询到数据,因此这个文件就需要进行合并了。
文件的allowed_seeks在VersionSet::Builder::Apply函数中进行计算。
开始合并
实际的合并动作是在DBImpl::DoCompactionWork函数中完成的。
这个压缩过程中的迭代,用了很多个迭代器
Thread #2 [leveldb-demo] 95928 [core: 4] (Suspended : Step)
leveldb::Block::Iter::Next() at block.cc:139 0x7ffff7d925d2
leveldb::IteratorWrapper::Next() at iterator_wrapper.h:42 0x7ffff7d95e48
leveldb::(anonymous namespace)::TwoLevelIterator::Next at two_level_iterator.cc:114 0x7ffff7d99196
leveldb::IteratorWrapper::Next() at iterator_wrapper.h:42 0x7ffff7d95e48
leveldb::(anonymous namespace)::TwoLevelIterator::Next at two_level_iterator.cc:114 0x7ffff7d99196
leveldb::IteratorWrapper::Next() at iterator_wrapper.h:42 0x7ffff7d95e48
leveldb::(anonymous namespace)::MergingIterator::Next at merger.cc:81 0x7ffff7d956df
leveldb::DBImpl::DoCompactionWork() at db_impl.cc:955 0x7ffff7d6f12d
leveldb::DBImpl::BackgroundCompaction() at db_impl.cc:685 0x7ffff7d6dc62
leveldb::DBImpl::BackgroundCall() at db_impl.cc:611 0x7ffff7d6d57e
leveldb::DBImpl::BGWork() at db_impl.cc:604 0x7ffff7d6d4f4
leveldb::(anonymous namespace)::PosixEnv::BGThread at env_posix.cc:661 0x7ffff7da007c
leveldb::(anonymous namespace)::PosixEnv::BGThreadWrapper at env_posix.cc:598 0x7ffff7d9fcd6
start_thread() at pthread_create.c:477 0x7ffff77b6609
clone() at clone.S:95 0x7ffff7a4129307. 多种Iterator实现
leveldb中有多种Iterator实现:
- Block::Iter。实现了对sstable内部block的访问。
- MemTableIterator。实现了对memtable的迭代遍历,由于memtable由skiplist实现,因此内部封装了对skiplist的迭代访问。
- TwoLevelIterator。组合迭代器,有两层。
- Version::LevelFileNumIterator。对有序的sst文件们的访问。
- MergingIterator。用于compact过程的迭代器。
08. 系统api与一些库函数的使用
fread_unlocked
顺序读read内部实现调用了fread_unlocked函数,该函数在读取文件时不会锁住文件流,因此外部的并发访问需要自行提供并发控制。需要注意的是,该函数是 GNU 的一个扩展,在 Unix 系统,例如 MacOS,FreeBSD,Soloris 中并无定义,因此作者使用了宏来控制fread_unlocked的定义。fopen
FILE* fopen(const char *path, const char *mode); // 打开文件memcmp
原型: int memcmp(void *buf1, void *buf2, unsigned int count);
比较内存区域buf1和buf2的前count个字节。结果已返回大于0还是小于0来表示比较的大小。 #include <string.h>。snprintf
C 库函数 int snprintf(char *str, size_t size, const char *format, …) 设将可变参数(…)按照 format 格式化成字符串,并将字符串复制到 str 中,size 为要写入的字符的最大数目,超过 size 会被截断。
原型:
int snprintf ( char * str, size_t size, const char * format, ... );#include <stdio.h>。
vsnprintf
头文件:#include <stdarg.h>
函数原型:int vsnprintf(char *str, size_t size, const char *format, va_list ap);函数说明:将可变参数格式化输出到一个字符数组
fwrite
C 标准库 - <stdio.h>size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)把 ptr 所指向的数组中的数据写入到给定流 stream 中。
参数
ptr – 这是指向要被写入的元素数组的指针。
size – 这是要被写入的每个元素的大小,以字节为单位。
nmemb – 这是元素的个数,每个元素的大小为 size 字节。
stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输出流。
返回值
如果成功,该函数返回一个 size_t 对象,表示元素的总数,该对象是一个整型数据类型。如果该数字与 nmemb 参数不同,则会显示一个错误。fflush
C 标准库 - <stdio.h>
int fflush(FILE *stream)C 库函数 int fflush(FILE *stream) 刷新流 stream 的输出缓冲区。
gettimeofday
<sys/time.h>
int gettimeofday(struct timeval*tv,struct timezone *tz )gettimeofday()会把目前的时间用tv 结构体返回,当地时区的信息则放到tz所指的结构中
timeval 结构体定义:
struct timeval{ long tv_sec; /*秒*/ long tv_usec; /*微妙*/ };
localtime_r
<time.h>
struct tm *localtime_r(const time_t *timep, struct tm *result);把从1970-1-1零点零分到当前时间系统所偏移的秒数时间转换为本地时间,而gmtimes函数转换后的时间没有经过时区变换,是UTC时间 。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!